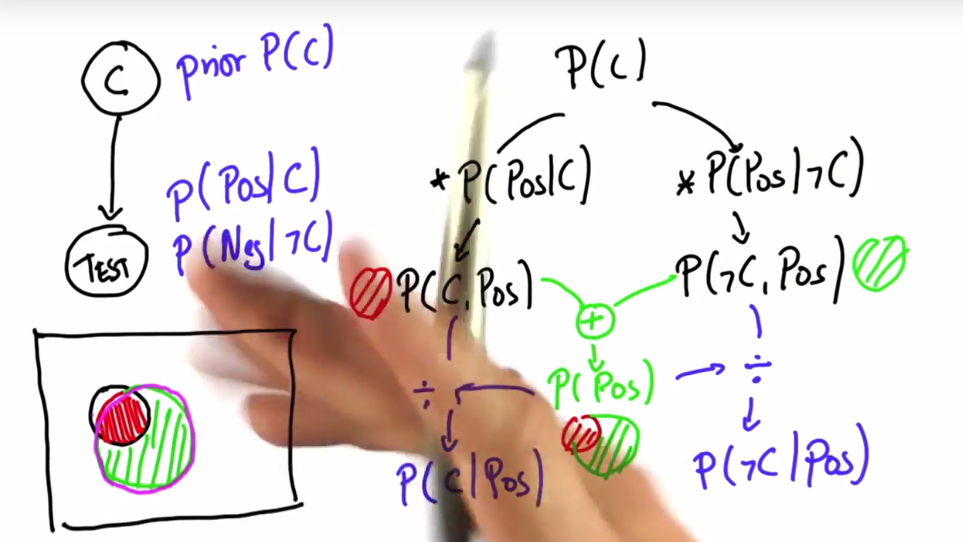
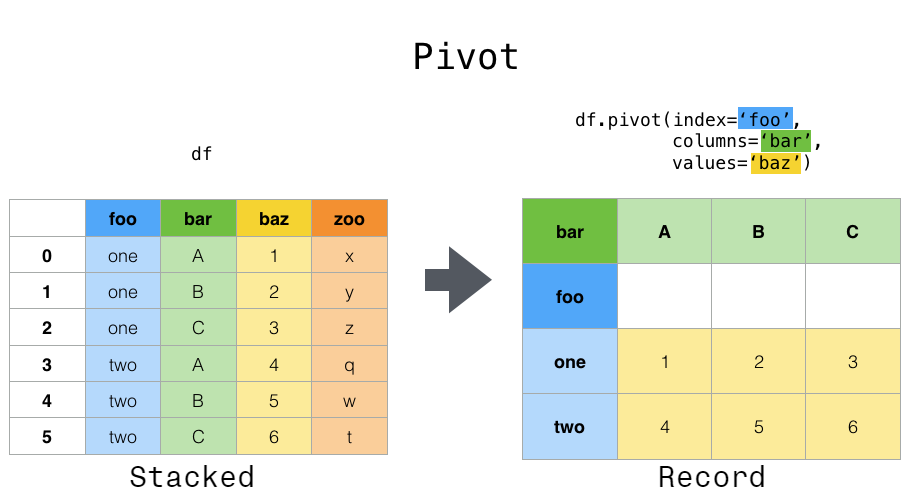
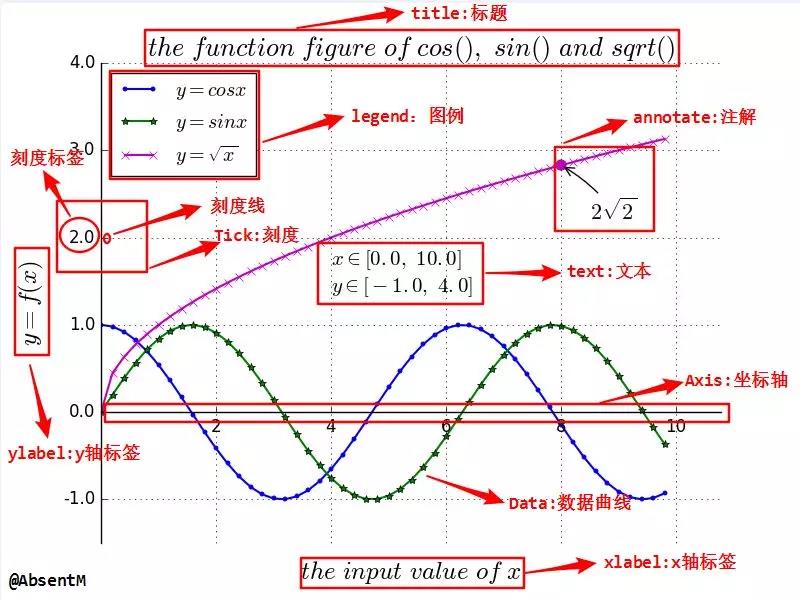
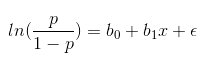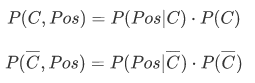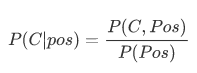import numpy as np import matplotlib.pyplot as plt
np.random.seed(42)
defMSEStep(X, y, W, b, learn_rate = 0.001): """ This function implements the gradient descent step for squared error as a performance metric. Parameters X : array of predictor features y : array of outcome values W : predictor feature coefficients b : regression function intercept learn_rate : learning rate Returns W_new : predictor feature coefficients following gradient descent step b_new : intercept following gradient descent step """ # compute errors # the squared trick formula y_pred = np.matmul(X, W) + b #Attention:the order of X and W error = y - y_pred #y_pred is a 1-D array,so is the error # compute steps W_new = W + learn_rate * np.matmul(error, X) #Attention:the order of X and error b_new = b + learn_rate * error.sum() return (W_new, b_new)
defminiBatchGD(X, y, batch_size = 20, learn_rate = 0.005, num_iter = 25): """ This function performs mini-batch gradient descent on a given dataset. Parameters X : array of predictor features y : array of outcome values batch_size : how many data points will be sampled for each iteration learn_rate : learning rate num_iter : number of batches used Returns regression_coef : array of slopes and intercepts generated by gradient descent procedure """ n_points = X.shape[0] W = np.zeros(X.shape[1]) # coefficients b = 0# intercept # run iterations #hstack为水平堆叠函数 为什么要堆叠呢? #类似zip,可以实现for W,b in regression_coef:print W,b来提取W和b regression_coef = [np.hstack((W,b))] for _ in range(num_iter): #从0-100中随机选择batch_size个数,作为batch batch = np.random.choice(range(n_points), batch_size) #按照batch从X中选出数据 X_batch = X[batch,:]#为2-D矩阵 y_batch = y[batch]#为1-D数组 W, b = MSEStep(X_batch, y_batch, W, b, learn_rate) regression_coef.append(np.hstack((W,b))) return (regression_coef)
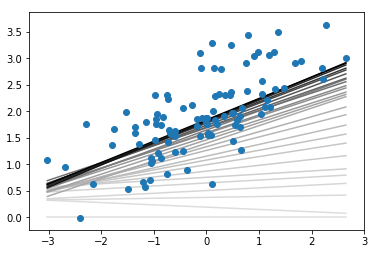
if __name__ == "__main__": # perform gradient descent data = np.loadtxt('data.csv', delimiter = ',') X = data[:,:-1]#提取第一列,为2-D矩阵 y = data[:,-1]#提取第二列,为1-D数组 regression_coef = miniBatchGD(X, y) # plot the results plt.figure() X_min = X.min() X_max = X.max() counter = len(regression_coef) for W, b in regression_coef: counter -= 1 #color为[R,G,B]的列表,范围都在0-1之间,[0,0,0]为黑色,[1,1,1]为白色 color = [1 - 0.92 ** counter for _ in range(3)] #绘制一条点(X_min,X_min * W + b)与点(X_max, X_max * W + b)之间的一条直线 plt.plot([X_min, X_max],[X_min * W + b, X_max * W + b], color = color) plt.scatter(X, y, zorder = 3) plt.show()
-- 查询一 SELECT cust_name,cust_email FROM customers WHERE cust_state IN ('str1','str2');
--查询二 SELECT cust_name,cust_email FROM customers WHERE cust_name = 'str3';
使用UNION链接
1 2 3 4 5 6 7 8
SELECT cust_name,cust_email FROM customers WHERE cust_state IN ('str1','str2') UNION SELECT cust_name,cust_email FROM customers WHERE cust_name = 'str3' ORDERBY cust_name;
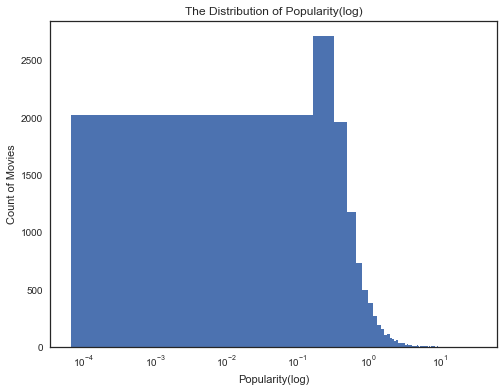
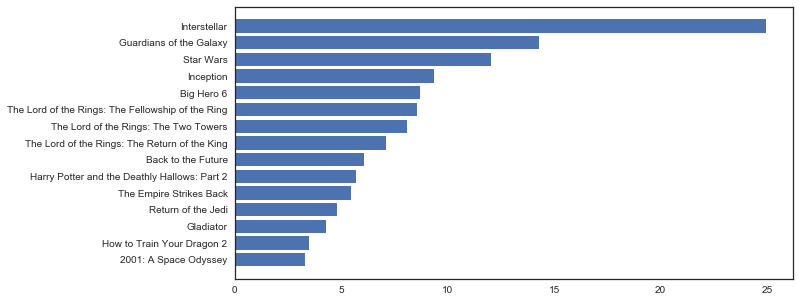
#受欢迎程度的分布情况 df_clean['popularity'].plot(kind = 'hist',bins = 200,title = 'The Distribution of Popularity(log)',logx = True,figsize = (8,6))#这里采用了x轴的对数坐标,考虑下为什么呢? plt.ylabel('Count of Movies') plt.xlabel('Popularity(log)');
1 2 3 4
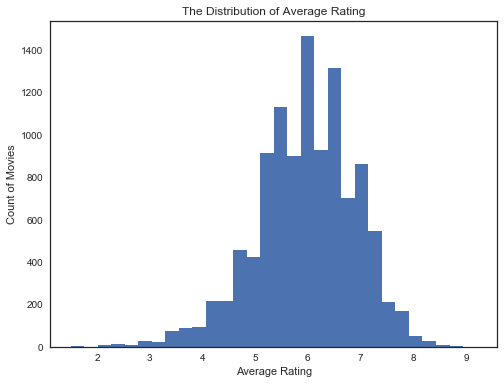
#平均评分的分布情况 df_clean['vote_average'].plot(kind = 'hist',bins = 30,title = 'The Distribution of Average Rating',figsize = (8,6))#这里就是用的普通的x轴坐标,为什么呢? plt.ylabel('Count of Movies') plt.xlabel('Average Rating');