Awareness is the greatest agent for change.
Hi,同学们,经过了前两周的学习,我们掌握了数据分析的基本流程、Pandas在数据分析各个流程中的基本应用以及使用matplotlib&Pandas进行可视化的技巧,那么本周我们就真刀实枪地找一套数据集练练手。本周的导学有两期,分别选用了项目三中的两个数据集(TMDb电影数据和FBI枪支数据)进行分析,只是分享思路和方法,起一个抛砖引玉的作用,大家选择其他的数据集也可以举一反三,如果有什么棘手的问题随时微信联系我就OK~
本周开始,我们就进入到了项目三(P3)阶段,本阶段总共包含四周,在这一个月内,我们要对数据分析入门进行学习,学习数据分析思维,掌握Python数据分析及可视化方法,并使用所学知识完成项目三:探索数据集,尝试着自己完成整个数据分析的流程,得到一些饶有兴趣的结论,你一定会非常有成就感哒!那么以下便是这四周的学习安排:
| 时间 | 学习重点 | 对应课程 |
|---|---|---|
| 第1周 | 数据分析过程-1 | 数据分析过程&案例研究-1 |
| 第2周 | 数据分析过程-2 | 案例研究-1&案例研究-2 |
| 第3周 | 完成项目 | 项目:探索数据集 |
| 第4周 | 项目修改与通过 | 修改项目、查缺补漏、休息调整 |
!!看这里!!:在P3课程里面安排了SQL的高阶课程,但是因为在项目三中并不会涉及到SQL知识,所以为了保证大家学习的连贯性,在完成前两周的课程之后,就开始项目。至于!!SQL的高阶知识,大家可以放在课程通关后进行选修!!;
本阶段可能是个挑战,请一定要保持自信,请一定要坚持学习和总结,如果遇到任何课程问题请参照如下顺序进行解决:
- 先自行查找问题答案(注意提取关键词),参考:谷歌/百度搜索、菜鸟教程、CSDN、stackoverflow、Python for Data Analysis, 2nd Edition 、Python Cookbook
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
饭要一口一口吃,路要一步一步走,大家不要被任务吓到,跟着导学一步一步来,肯定没问题哒!那我们开始吧!
注:本着按需知情原则,所涉及的知识点都是在数据分析过程中必须的、常用的,而不是最全面的,想要更丰富,那就需要你们课下再进一步的学习和探索!
本周目标
- 在此处挑选和你确认过眼神的数据集,并对其进行数据分析和探索,得出你自己的结论,然后进行提交。
学习计划
| 时间 | 学习资源 | 学习内容 |
|---|---|---|
| 周二 | 微信群 - 每周导学 | 预览每周导学 |
| 周三、周四 | Udacity - Classroom | 项目三 |
| 周五 | 微信/Classin - 1V1 | 课程难点 |
| 周六 | Classin - 优达日 | 本周学习总结、答疑 |
| 周日 | 笔记本 | 总结沉淀 |
| 周一 | 自主学习 | 查漏补缺 |
项目准备
环境准备
强烈建议大家完成本地环境的搭建,在本地完成此项目。搭建本地环境的方法请参考Anaconda的安装与配置一节,完成后你将获得本项目中会用到的关键软件:Spyder和Jupyter Notebook。
文件准备
- 项目文件:依次进入到项目:探索数据集 –> 3.实战项目中,下载项目文件的ipynb格式。
数据集选择:在此处选择你感兴趣的数据集并下载至与项目文件相同的文件夹。(若下载失败,请微信联系我索取)
本地打开:在项目文件的文件夹下,按住
Shift键,右击选择在此处打开命令窗口,输入jupyter notebook,待打开本地页面之后,选择项目文件打开,之后就请开始你的表演。
方法准备
项目文件中已经给大家列好了基本流程,所以请在开始项目之前,一定要先整体浏览一遍项目文件,着重看一下:
- 项目流程
- 每一个流程中你需要做哪些工作
- 每一个流程中的提示
要记得,数据分析过程不是一蹴而就的,是螺旋上升接近目标的过程,所以一定要保持耐心,对照着项目评估准则一步步完成。
另外,一开始你的notebook会显得很乱没有章法,那在提交之前最好能再修改一个整理好的版本。
项目流程(TMDb)
数据集说明
本项目选择的数据集为Kaggle提供的TMDb电影数据。此数据集中包含 1 万条电影信息,信息来源为“电影数据库”(TMDb,The Movie Database),包括用户评分和票房等。数据已进行了简单清理,涉及到的变量如下表所示:
| 变量名 | 注释 | 变量名 | 注释 |
|---|---|---|---|
| id | 电影序号 | keywords | 电影关键词 |
| imdb_id | imdb电影序号 | overview | 剧情摘要 |
| popularity | 受欢迎程度 | runtime | 电影时长(min) |
| budget | 预算($) | genres | 电影风格 |
| revenue | 收入 | production_companies | 制作公司 |
| original_title | 电影名称 | release_date | 发布日期(月/日/年) |
| cast | 演员表 | vote_count | 评价次数 |
| homepage | 电影网址 | vote_average | 平均评分 |
| director | 导演 | release_year | 发布年份 |
| tagline | 宣传词 | budget_adj | 预算(考虑通胀) |
| revenue_adj | 收入(考虑通胀) |
提出问题
对数据简单浏览之后,你要进行角色扮演了,假如你现在就是一名电影行业的数据分析师,通过分析此数据集,你能为公司提供哪些有用的发现或者规律呢?或者你只是一名会数据分析的电影爱好者,通过分析此数据集,你能否给小伙伴们推荐一些合适的电影呢?这里提供几个参考:
电影类型相关:
- 哪些类型的受欢迎程度最高?随着时间推移有什么变化呢?
- 随着时间的推移,各类型的数量身上有什么变化呢?
- 哪些类型赚钱最多?投资收益比呢?
- 哪些类型拍摄的数量最多?
导演相关:
- 哪些导演最能吸金?
- 哪些导演的电影平均评分最稳定或者最高?
制作公司相关:
- 哪些公司最能赚钱?最能赚口碑?评分最稳定或者最高?
影响电影评分的要素有哪些?
影响电影收益的要素有哪些?
最近几年的电影都有哪些关键词?
……
整理好你感兴趣的问题后,那就开始吧~
在本示例中,选择的主题为今晚有空,让好电影与你相伴,所以我们的目标就是筛选出好看的电影咯~
导入拓展包
一般来说,就导入如下几个拓展包就够了,当然如果后续操作中还需导入其他包的话,再补充即可。
1 | # 用这个框对你计划使用的所有数据包进行设置 |
数据整理
导入数据
1 | df = pd.read_csv('tmdb-movies.csv') |
评估数据
- 列及数据类型
1 | df.info() |
1 | <class 'pandas.core.frame.DataFrame'> |
纵然了一下,各列的数据类型没什么问题,唯一一个可能有问题的是release_date列,应该是datetime类型,但因为我们后面的分析中只会用到电影的上映年份,也就是release_year列,所以这列不处理也罢。
- 查看各列的缺失值情况
1 | df.isnull().sum() |
1 | id 0 |
可见数据集的情况很不错,几个关键列几乎没有缺失。至于director列的缺失,你可以依照电影标题去搜索它的导演,然后进行填充,或者干脆直接删除掉。
- 查看重复值
1 | sum(df.duplicated()) |
1 | 1 |
有一行重复数据,过会儿直接清理掉。
- 查看基本数据统计情况
1 | df.describe() |
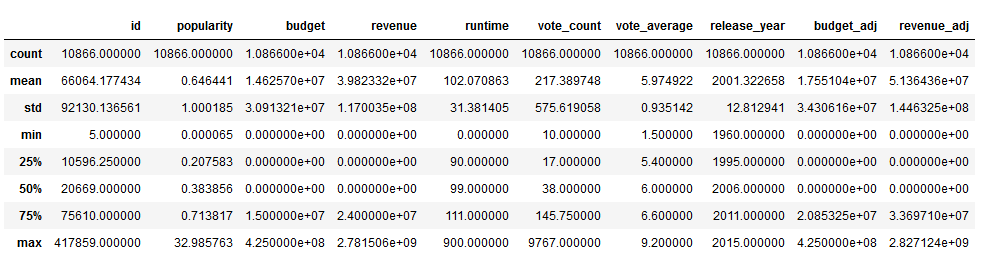
因为这是在数据评估阶段,所以着重看min和max,检查是否有异常值。本数据集中没什么问题。
查看各列元素
1
df['column_name']
可以查看各列的详细情况,避免因为折叠而忽略了某些严重问题。
比如说,我们通过查看各列情况,发现cast、keywords、genres和production_companies这四列中的都包含有以|分隔开的多个平级元素,这在进行之后的按类分析时会非常不便,所以需要清理。(但也不是这四列都要清理,只用清理你的分析中会用到的就行。)

还有就是budget_adj和revenue_adj两列是科学记数法,在进行可视化的时候,坐标轴的显示肯定就会很丑,到时候要注意处理。
清理数据
清理数据就是对上一步中发现的问题进行清理,并且删除无关列,最终得到的是一个方便你进行分析及可视化的干净数据。
清理前记得备份数据
数据备份
1
df_clean = df.copy()
删除无关列
在本次示例项目中,我们的目的是找出好看的电影,所以评分和受欢迎程度是关键参数,然后再探索下他们与其他参数之间是否存在联系。
那就按照如下方法删除一些无关列(其实是筛选出想要的列,顺便再拍一下序):
1
df = df[['original_title','production_companies','director','cast','genres','keywords','runtime','popularity','vote_count','vote_average','release_year','budget_adj','revenue_adj']]
缺失值的处理
因为关键列并没有出现数据缺失,所以并未进行处理。
删除重复值
1
df.drop_duplicates(inplace = True)
genres列处理电影类型是关键筛选条件,所以要细分。
1
2#将genres列转为str格式(因为NaN是float格式的)
df_clean.genres = df_clean.genres.astype(str)1
2
3
4#获取所有的电影类型
genres_set = set() #定义空集合
for x in df_clean['genres']:
genres_set.update(x.split('|'))1
2#从genres_set中删除nan
genres_set.remove('nan')1
2
3#将各电影类型作为列添加到数据集中,并用1表示‘是’,0表示‘否’
for genres in genres_set:
df_clean[genres] = df_clean['genres'].str.contains(genres).apply(lambda x:1 if x else 0)1
2
3#删除genres列,并检查
df_clean.drop('genres',axis = 1,inplace = True)
df_clean.head(3)production_companies列处理属于电影的参考列,所以我们只筛选首公司。
1
2#只筛选第一家主要投资的公司
df_clean.production_companies = df_clean.production_companies.str.split('|').str[0]1
2#为了符合逻辑,更改列名
df_clean.rename(columns = {'production_companies':'production_company'},inplace = True)cast列处理演员也是电影的参考列,只筛选出两名主演。
1
2
3
4
5#筛选前两位主演
df_clean['major_actor_1'] = df_clean.cast.str.split('|').str[0]
df_clean['major_actor_2'] = df_clean.cast.str.split('|').str[1]
#删除cast列
df_clean.drop('cast',axis = 1,inplace = True)添加
income_adj列原数据中只有
budget_adj和revenue_adj列,后者减去前者即为电影的收益。1
df_clean['income_adj'] = df_clean['revenue_adj'] - df_clean['budget_adj']
至此,清理数据告一段落。
探索性数据分析
在这个阶段你可以随意做可视化,尽可能多得去探索你想解决的问题。在探索阶段,作图可以不用很规范,你自己知道是什么意思就可以,而且可能会有些探索的问题结果意义不大,所以在提交项目时,要进行择优保留并对其润色修饰。
探索受欢迎程度及评分
电影的受欢迎程度和平均评分是我们在进行电影推荐时的主要参考,所以我们先来观察下这两列的主要分布情况以及与其他列的相关性。
- 分布情况
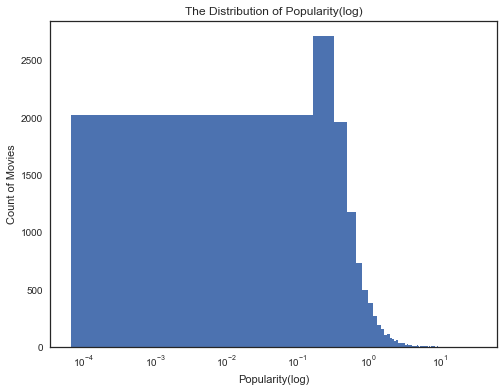
1 | #受欢迎程度的分布情况 |
1 | #平均评分的分布情况 |
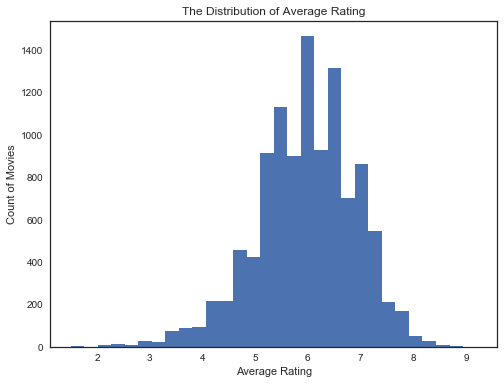
通过观察这两幅图我们可以发现:绝大部分的电影受欢迎程度都在10以下,平均评分却是一个类正态分布,电影评分集中在5到7之间。
与上映年份的关系
1
2
3#受欢迎程度
df_clean.groupby('release_year')['popularity'].mean().plot(kind = 'line')
plt.hlines(df_clean['popularity'].quantile(.75),xmin = 1960,xmax = 2015,color = 'red');
1
2
3#评分
df_clean.groupby('release_year')['vote_average'].mean().plot(kind = 'line')
plt.hlines(df_clean['vote_average'].quantile(.75),xmin = 1960,xmax = 2015,color = 'red');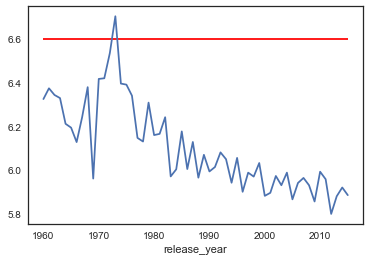
通过观察这两幅可视化,我们发现:随着上映日期逐渐接近现在,受欢迎程度呈波动上升趋势,但是评分却是波动下降。这应该是因为年代越久远的电影观看人数越少,评分次数也就越少(需附图验证),个别的高评分对平均评分的影响也就越大,这才导致了受欢迎程度低却评分高的现象。
- 与其他数值型变量的关系
本数据集中的数值型变量不是很多,但要是一对一对的去看他们之间的相关性会很累,懒人智者推动科技进步嘛,前辈们帮我们都考虑好了,可以参考下面的代码:
1 | #筛选出数值变量 |
各变量之间相关性的热度图
1 | fig, ax = plt.subplots(figsize=(10, 6)) |
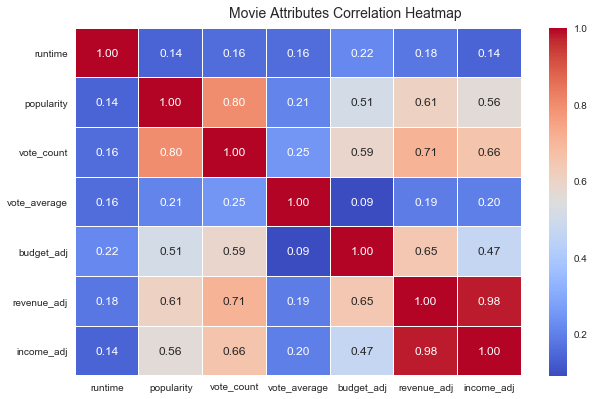
从这幅图里面,可以很明显的读出一些信息:
- 受欢迎程度与评分人数有较强的正相关关系,与收益的正相关程度也稍强,这很好理解;
- 平均评分却鲜有相关的变量,那影响评分的因素都有哪些呢?(导演?主演?制片公司?)
pairplot
你不满足于只看冷冰冰的数字,想看到更直观的散点图或者直方图,那就请参考如下代码:
1 | pp = sns.pairplot(df_corr, size=1.8, aspect=1.8, plot_kws=dict(edgecolor="k", linewidth=0.5), diag_kind="kde", diag_kws=dict(shade=True)) |
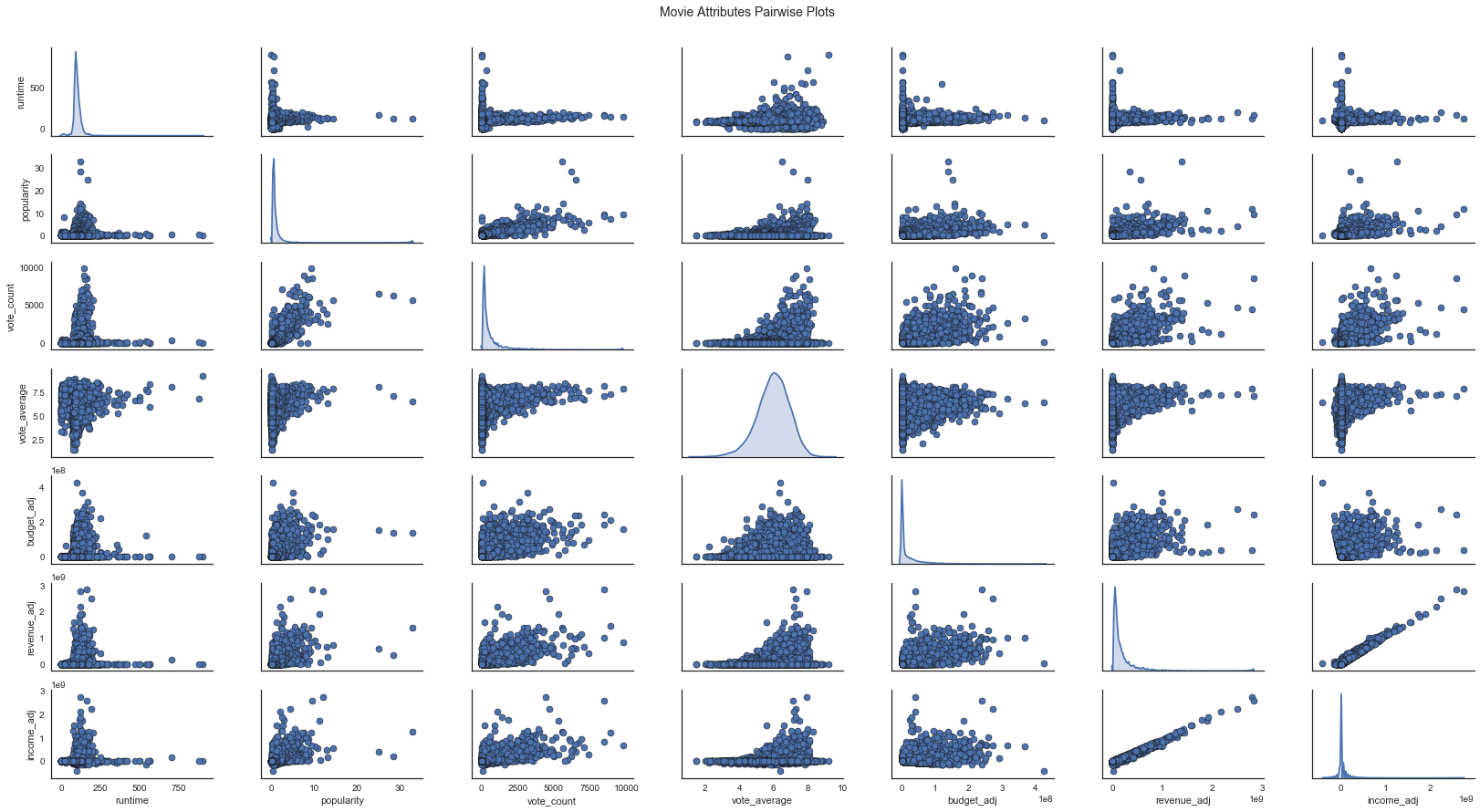
从上面这幅可视化中,我们不仅能看到各变量两两之间的散点图(相关性),还能看到各变量的分布情况,真可谓是大杀器。
那,热度与评分和其他分类变量有没有什么关系呢?
…(请继续探索)
… KEEP GOING
电影推荐
在做电影推荐时,受欢迎程度和评分是我们的关键评估指标。
- 按电影类型推荐
比如说,你有一个哥们比较喜欢看Adventure类的电影,听说你在做TMDb的电影数据分析,所以来找你推荐,你会推荐哪些呢?
1 | #首先我们要筛选出Adventure类的电影 |
1 | #既然是推荐,自然要筛选一些热门的评分高的电影,所以这里我们选择了好于其他90%的电影(结果为15部电影) |
1 | #排序 |
1 | #可视化 |
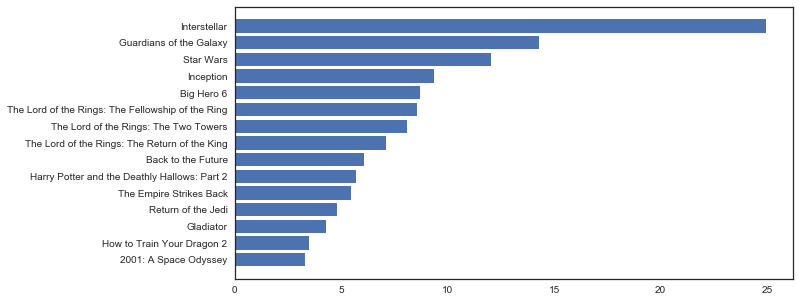
结论立马就出来了,首推的电影就是Interstellar(星际穿越)。当然这种方法可以定义成一个函数,参数即为电影类型,这样就能省心省力的得到所有电影的最热最佳推荐了。
当然,你还可以尝试:
按导演推荐
我一开始想着用groupby直接按照导演分类,然后求评分的均值再作图,可是结果并不如人意。
1 | df_clean.groupby('director')['vote_average'].mean().sort_values()[-15:].plot(kind = 'barh',color = 'b'); |

这些导演好像都不是很熟悉,应该是数据集中只收录了一部或者很少的电影作品,然而又因为这些作品的评分较高,才导致这种情况,所以我们要先对导演做一个筛选,比如说,筛选出收入作品数量在10部及以上的导演。
1 | #先对原数据中的director列作计数统计,然后筛选大于等于10的数据存为一个新的DataFrame(目的是为了方便筛选) |
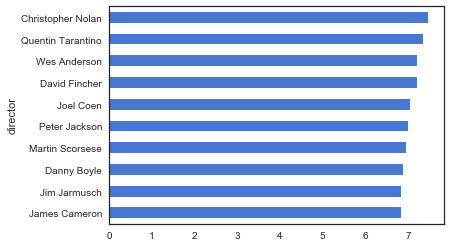
1 | #受欢迎程度 |
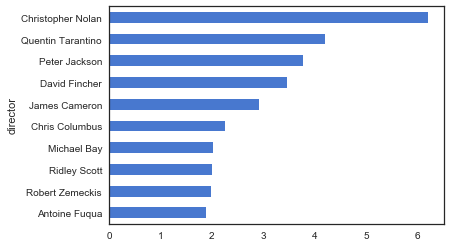
这次得到的结果更大众一些,出现的导演名字也基本都听过。Christopher Nolan和Quentin分别获得了双料榜首和榜眼,这两个人的名字也算是电影的品质保证了吧。
按主演推荐
按制片公司推荐
… …
当然,你还可以分析电影评分与其他变量的相关性,或者从效益角度出发,去分析票房、预算、收益等等。但万变不离其宗,用数据分析的流程做指导,所学知识为基础,Bing或者Google为利剑(搜索的时间可能要占到一半以上,所以不要慌,搜索完记在小本本上),开始你的项目三征服之路吧!
得出结论
对你整理好的可视化图像进行总结,结论要有根有据但也不要只是停留在描述,可以进行适当的猜测。
最后
- 导学只是参考和分享,我是还原了自己在做项目时的思路历程,这并不是提交项目时应有的样子。
- 记得提交前一定要再重新审视一遍,调整代码,注释,修缮可视化及结论。
- 经过P3的历练,相信你能更自信,也更能有成就感,坚持!!
- 加油!!!