If you tell yourself you can’t, you won’t.
Hi,同学们,上一阶段我们学习了数据分析的基本流程、Pandas在数据分析各个过程中的应用以及Matplotlib&Pandas的可视化基础,截至目前,你们已经算是掌握了基础的数据分析技能啦!撒花!但是在统计学理论和预测方面仍有欠缺,那么P4阶段就是解决这个欠缺哒!
本周开始,我们就进入到了项目四(P4)阶段,本阶段总共包含三周,在这三周内,我们要对统计学进行学习,掌握基础的描述统计学理论、基本的概率知识、二项分布和贝叶斯公式,并学会使用 Python 来实践;学习正态分布、抽样分布、置信区间以及假设检验的概念和计算方式;学习线性回归以及逻辑回归,在真实场景中应用,比如分析 A/B 测试结果,搭建简单的监督机器学习模型。可谓是时间紧任务重,但是也别怕,统计学的基础知识还是非常简单的,跟着课程内容一步步来,自己多做笔记多查资料,一定没问题的!
那么我们的课程安排:
| 时间 | 学习重点 | 对应课程 |
|---|---|---|
| 第1周 | 统计学基础 | 描述统计学 - 抽样分布与中心极限定理 |
| 第2周 | 统计学进阶 | 置信区间 - 逻辑回归 |
| 第3周 | 完成项目 | 项目:分析A/B测试结果 |
本阶段可能是个挑战,请一定要保持自信,请一定要坚持学习和总结,如果遇到任何课程问题请参照如下顺序进行解决:
- 先自行查找问题答案(注意提取关键词),参考:谷歌/必应搜索、CSDN、stackoverflow
- 额外参考资料:
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
饭要一口一口吃,路要一步一步走,大家不要被任务吓到,跟着导学一步一步来,肯定没问题哒!那我们开始吧!
注:本着按需知情原则,所涉及的知识点都是在数据分析过程中必须的、常用的,而不是最全面的,想要更丰富,那就需要你们课下再进一步的学习和探索!
本周目标
学习课程中的描述统计学 - 抽样分布与中心极限定理课程,掌握统计学基础知识。
学习计划
| 时间 | 学习资源 | 学习内容 |
|---|---|---|
| 周二 | 微信群 - 每周导学 | 预览每周导学 |
| 周三、周四 | Udacity - Classroom | 描述统计学 - 抽样分布与中心极限定理 |
| 周五 | 微信/Classin - 1V1 | 课程难点 |
| 周六 | Classin - 优达日 | 本周学习总结、答疑 |
| 周日 | 笔记本 | 总结沉淀 |
| 周一 | 自主学习 | 查漏补缺 |
本周知识清单
描述统计学基础
描述统计分析就是通过数字或可视化的方法,对数据集进行整理、分析,并对数据的分布状态、数字特征和随机变量之间的关系进行估计和描述。其简要可以分为集中趋势分析、离散程度分析以及相关分析三大部分。所以,虽然这部分是选修内容,但拜托各位一定要看,这部分理论是数据分析的基础。
数据类型
数据类型是基础,尤其是之后在进行回归预测时,针对不同的数据类型可以选择不同的算法,所以必须掌握。
数据类型可以分为两大类:数值和分类;进而分为四小类:连续、离散、定序和定类。
| 数据类型 | ||
|---|---|---|
| 数值: | 连续 | 离散 |
| 身高、年龄、收入 | 书中的页数、院子里的树、咖啡店里的狗 | |
| 分类: | 定序 | 定类 |
| 字母成绩等级、调查评级 | 性别、婚姻状况、早餐食品 |
描述统计的量
| 数据类型 | 描述方面 | 描述方式 | 备注 |
|---|---|---|---|
| 数值: | 集中趋势 | 均值 | |
| 中位数 | 偶数个时取中间两值均数 | ||
| 众数 | 存在没有或多个的可能 | ||
| 离散程度 | 极差 | max - min | |
| 四分位差(IQR) | 75%数 - 25%数 | ||
| 方差 | 每个观察值与均值之差平方和的平均数 | ||
| 标准差 | 方差的平方根 | ||
| 数据形状 | 左偏态 | 均值小于中位数(普遍但不绝对,下同) | |
| (需做直方图) | 右偏态 | 均值大于中位数 | |
| 对称分布(通常是正态分布) | 均值等于中位数 | ||
| 异常值 | 一般为上下超过1.5倍四分位差 | 处理方式见下面【异常值的处理】 | |
| 分类: | 分类计量个数或比例 |
偏态分布示意图
其他概念:
五数概括描述法:利用最小值、第一四分位数(25%处)、第二四分位数(中位数)、第三四分位数(75%处)和最大值五个数对数值型变量的离散程度进行描述的方法。
当我们的数据遵循正态分布时,我们可以使用
均值和标准差完全理解我们的数据集。但是,如果我们的数据集是偏态分布,
五数概括法(和关联的集中趋势度量)更适用于概括数据。除直方图外,你还可以使用箱线图进行统计描述,箱线图其实是五数概括法的可视化。
异常值的处理:
1. 至少注意到它们的存在并确定对概括统计的影响。
2. 如果是输入错误 — 删除或改正
3. 理解它们为何存在,以及对我们想要回答的关于数据的问题的影响。
4. 当有异常值时,报告五数概括法的值通常能比均值和标准差等度量更好地体现异常值的存在。
5. 报告时要小心。知道如何提出正确的问题。
随机变量
随机变量集用大写字母,如X表示;
而集里面的某个变量用对应的小写字母,如x1,x2等表示。
推论统计学基础
推论统计就是根据现有收集的部分数据对更大的总体数据进行推论的方法。他的几个关键要素为:
- 总体 —— 我们想要研究的整个群体。
- 参数 —— 描述总体的数值摘要
- 样本 —— 总体的子集
- 统计量 —— 描述样本的数值摘要
辛普森悖论
本节以录取案例分析为例,展示了辛普森悖论。这个例子不必深究,只是为了提醒大家要以多种方式去观察数据,避免出现案例分析中的反例。
辛普森悖论是在某个条件下的两组数据,分别讨论时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。那么如何避免辛普森悖论呢?那就要从产生它的源头——混杂因素上考虑,混杂因素就是一个与核心研究无关的变量,它会随着变量的改变而改变,就比如说在课程中的例子中,不同专业的总人数就有很大差异,它会随着专业的改变而改变。所以在之后处理类似问题时就要进行多变量分析,这样才能帮助我们认清事件的本质。
概率
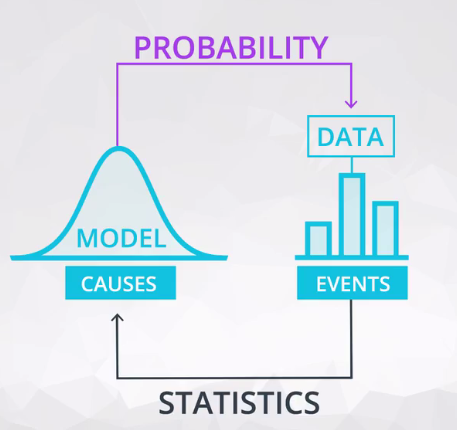
概率与统计的关系
从课程中给的这幅关系图就能很明显的看出来,概率是由模型(MODEL)去预测数据(DATA),而统计是由数据去建立模型(进而再去做预测,也就是‘’根据数据去预测数据’‘)。
基础知识
概率,是一种几率、可能性,描述是事件发生的可能性度量量。随机事件,指一个被赋予机率的事件
集合,针对的是事件在样本空间的一个子集。事件A发生的概率,用符号P(A)表示 。
任何事件的发生概率在 0 和 1 之间,其中包括 0 和 1。(0表示不可能发生,1表示必然发生)
独立事件:事件每次发生的结果与前后的发生结果无关。比如说,第一次掷骰子的结果与第二次的结果
互斥事件:不可能在同一次实验中出现的俩事件。比如说,掷骰子实验中的1和6
对立事件:是一种特殊的互斥事件,即试验中只有俩种可能A和B,那么事情的发生非A即B。可以表示为
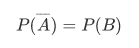
如掷硬币的正面和反面。
加法原理:若两种方法均能完成此事,则此事发生的概率为P(A) + P(B)
乘法原理:若两个步骤分别不能完成此事,则此事发生的概率为P(A)·P(B)
二项分布
也叫伯努利分布,是指n个独立的事件A发生的概率分布。设每次试验中事件A发生的概率为p,则进行n次试验,A发生k次的概率为:
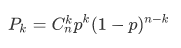
条件概率
在现实中,我们处理的事情并不像骰子和硬币那样简单,有些时间的结果往往依赖于其他的事情,比如说晨练的概率跟这个人是不是夜猫子有关等等。那么,这就引出了条件概率,即在事件B发生的条件下,事件A发生的概率为:
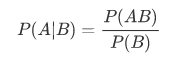
其中,P(AB)表示AB同时发生的概率。
在如下的文氏图中,AB同时发生的概率可以表示为两个圆的交集,那么B已经发生的条件下A发生的概率就是这个交集(橙色部分)占整个B圆的比例。
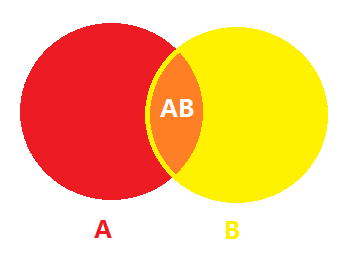
之前讲过独立事件,那么用公式的方式可以表达为:
P(A) = P(A|B)。根据条件概率公式可以推导出,当P(AB) = P(A)P(B)时,则可说明A事件与B事件相互独立。
全概率公式
也就是A发生的概率为在互斥的多个事件(B1,B2…)已发生的条件下的条件概率之和。公式可以表示为:
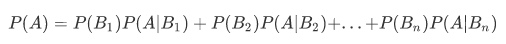
贝叶斯法则
贝叶斯法则是概率推理的黄金法则,是利用先验概率计算后验概率的方法。
课程中的癌症例子十分贴切,讲解的也十分详细,所以大家看到前20个小节,能理解贝叶斯法则就可以了,后面的是在无人驾驶中的应用例子,可以跳过不看。
在课程示例中:
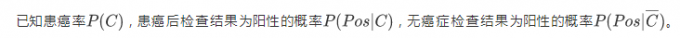
由条件概率能计算出患癌与检查结果为阳性同时发生的概率P(C,Pos)(红色区域占整个矩形的比例)和没患癌与检查结果同时发生的概率P(~C,Pos)(绿色区域占整个矩形的比例)。
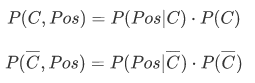
二者相加,即为检查结果为阳性的概率(全概率公式)P(Pos)。
则,检查结果为阳性的条件下患癌概率为:
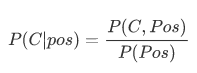
这样我们就得到了更接近真实的检查结果为阳性的患癌概率。
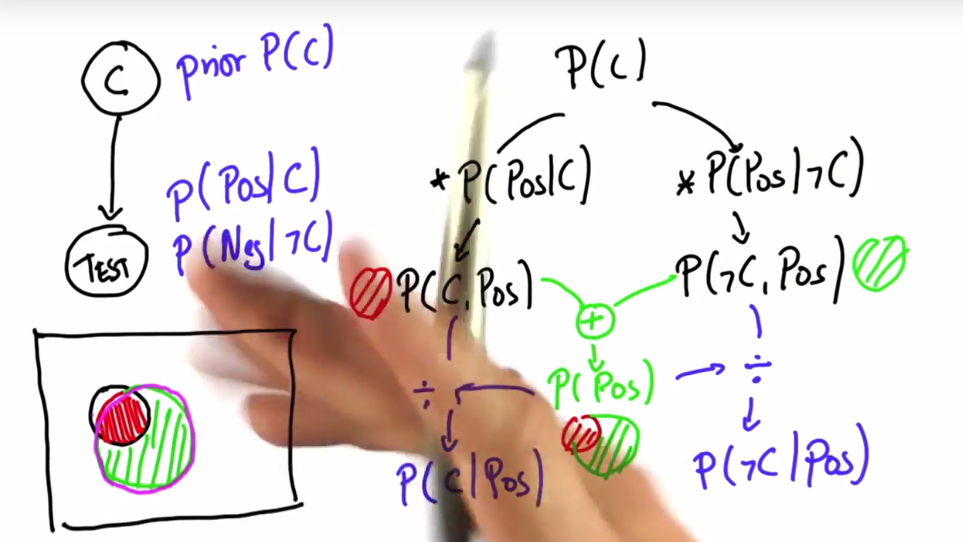
在这个例子中:
癌症发生的概率P(C)为先验概率,即在我们进行检查之前就对患癌概率的一个判断;
阳性结果下为癌症的概率P(C|Pos)为后验概率(阳性下非癌症、阴性癌症、阴性非癌症都是),这些是在检查发生之后,我们对患癌概率这件事的重新评估;
这就是贝叶斯法则的含义。我们先预估一个”先验概率”,然后加入实验结果,由此得到更接近事实的”后验概率”。
如果感觉理解困难,可以看一下白话版的贝叶斯讲解:怎样用非数学语言讲解贝叶斯定理(Bayes’s theorem)
Python概率练习
前面我们学习了概率的基本知识,有了理论基础,本节就是利用Python落地的教学。应用的第三方包为NumPy和Pandas。
均匀随机取整
使用的函数为numpy.random.randint(low, high=None, size=None, dtype='l'):
- low:当没有high参数输入时,作为取值范围的最大值+1;当有high参数输入时,则作为取值范围的最小值;
- high:取值范围的最大值+1,默认为无输入;
- size:输入数字则表示取值的数量,输入元组则表示取值矩阵的行和列;
- dtype:数据类型,默认为np.int;
- 函数的输出为int或者是由int数据类型组成的ndarray。
函数的具体用法如下:
1 | import numpy as np |
不均匀随机取数
使用的函数为numpy.random.choice(a, size=None, replace=True, p=None):
- a:输入列表时,取数就从该列表中取;若输入为数字时,取值范围为0到该数字 - 1;
- size:输入数字则表示取值的数量,输入元组则表示取值矩阵的行和列;
- replace:布尔值,默认为True,若设置为False表示取数不会重复;(以从袋子中取球为例,True是取完放回再取,而False则是取了不放回,继续取)
- p:表示概率,与a的输入值一一对应。
- 函数的输出为int或者是由int数据类型组成的ndarray。
函数的具体用法如下:
1 | #输入数字时取数 |
二项分布
使用的函数为numpy.random.binomial(n, p, size=None),参数也很好解释。
参数中的n即为每次试验中取值的次数,p则为试验中的某一种事件成功的概率,size则是试验的次数。
条件概率与贝叶斯规则测试
这里主要是一些Pandas函数的应用,经过上一阶段的学习应该已经很熟练了。
主要涉及的函数是分组和统计计数类的函数,比如说groupby,query,count等,如果忘记的话,自己查官方文档或者之前的笔记,这里不再赘述。
正态分布
课程中以抛硬币模型引入了二项分布进而讲解了正态分布模型,那么到底什么是正态分布或者满足什么条件就可以算是正态分布了呢?
在相同条件下,我们随机地对某一测试对象(抛硬币20次,其中正面的次数)进行多次测试(抛很多次20次)时,测得的数值在一定范围内波动(从0到20),其中接近平均值的数据(10左右)占多数,远离平均值的占少数。具有这种分布规律的随机变量的分布就称作正态分布。
大概长这样儿:
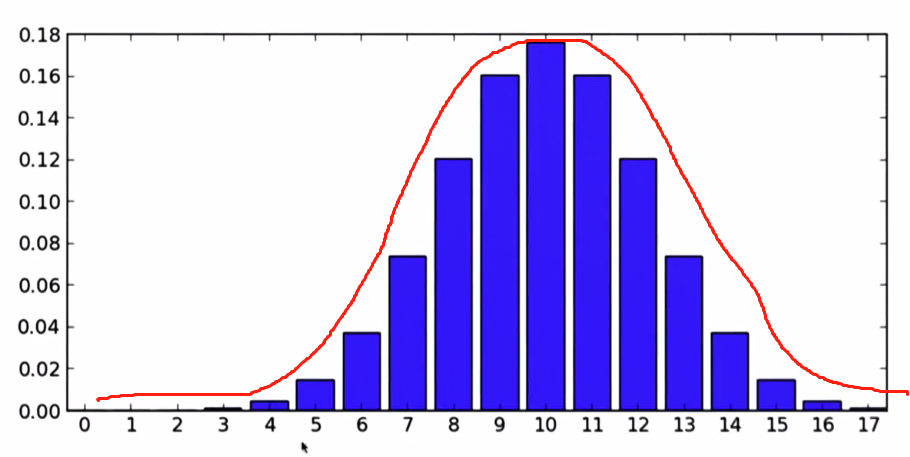
它的概率密度函数可以表示为:
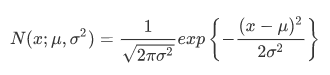
这里为什么要引入正态分布呢?
- 假设检验是基于正态分布的
- 许多社会和经济现象对应的随机变量分布,都可以用正态分布来描述
中心极限定理
在此之前,先回顾下推论统计的几个概念:
- 总体 —— 我们想要研究的整个群体。
- 参数 —— 描述总体的数值摘要
- 样本 —— 总体的子集
- 统计量 —— 描述样本的数值摘要
课程中举得例子是统计优达学生中喝咖啡的人所占比例,我们看下图:
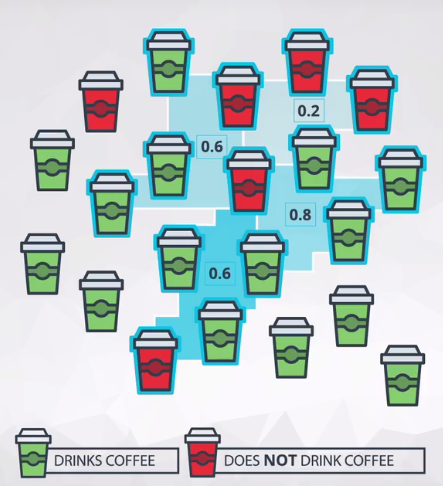
图中所有的杯子(学生)就叫做总体;此外可以看到有四个深浅不一的蓝色底框,每个底框链接了5个学生,这5个学生就是样本,每组样本我们还计算了喝咖啡的比例,这就是统计量。
一般的,样本数≥30即可称为大样本。 大样本条件下,抽样平均数的分布接近正态分布。
但必要抽样数目的确定是有相关公式计算的,这里就不给出了,感兴趣的话可以去搜搜看。
现在我们继续按照课程中的例子进行取样,样本容量为5,不断得取10000次,计算均值的分布情况如下:
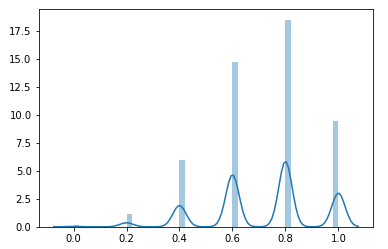
(完全看不出这是个什么分布)
将样本容量改为50,仍然取10000次,计算均值的分布情况如下:
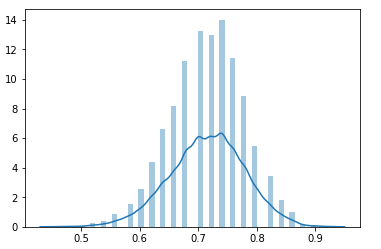
已经可以看出正态分布的样子了,那如果继续增加样本容量,改为5000,同样取10000次,计算均值的分布情况如下:

想比上一幅图,这幅可视化更接近正态分布,均值处于相同的位置,但方差(离散程度)明显小了很多。
上面的这个过程就是中心极限定理的含义,随着样本容量的逐渐增大,平均数的抽样分布越接近正态分布(但也不一定必须要很大很大才能近似于正态分布),同样这也适用于求和,比例等,但不适用于所有的统计量,比如说最大值,方差等等。
中心极限定理的妙处就在于,我们可以从任意的乱七八糟的分布取任意数量的样本值(比如上面例子中的5,50),然后计算样本的均值(或者和),不断得取值求均,最终做他们频率的可视化,你会发现这是一个非常完美的正态分布。
现实生活中有很多的随机过程,有的分布就是乱七八糟,但是你可以通过中心极限定理,得到他们均值或者和的正态分布,这也是为什么正态分布在统计中如此常用的原因之一。
如果感觉理解起来还是有点儿困难的话,你可以戳在线抽样分布模拟器,自己动手试一试。
大数定理
大数定理表达的是随着样本容量增加,样本平均数越来越接近总体平均数,字面上的意思很好理解,但这里有一点要注意,我们举例来说明一下:
比如说,我现在有100枚硬币,放在一个盒子里,随便摇一下盒子,打开,对正面朝上的硬币进行计数(当然,我们知道期望为100 x 0.5 = 50):
第一次实验的结果是55;第二次是60;第三次是70,三次实验的均值为((55+60+70)/3 ≈62),那你觉得,下次实验的结果是更有可能小于50还是大于50呢?
你有可能这样想,根据大数定理,随着我们试验次数的不断增加,均值肯定是不断趋向于50的,前三次的实验中每次都超过50,那么下次的实验会有更大的可能小于50,来纠正前三次实验的偏差。
如果你真的这样想,你就陷入了赌徒悖论。大数定理不关心前面发生的有限次实验,因为后面还有无限次的实验,而这无限次实验的期望值是50。这个例子可能比较随意,但这就是大数定理的含义。
自助法
自助法,bootstrap,也就是重复抽样。还记得上一节导学中讲到的numpy.random.choice函数吗?里面有一个replace参数,默认为True表示重复取样,也就是自助法;若设置为False,则表示不重复取样。
总结
本期导学主要对描述统计学和概率的基础知识进行了总结,这部分偏理论一些,如果觉得理解起来有点吃力,可以通过重复看视频,边看边用笔去算或者去网上搜集一些资料或者找一些教科书去查阅,要求是:不一定要完全掌握其原理,但求理解和会用。