A positive attitude causes a chain reaction of positive thoughts,events and outcomes.
Hi,同学们,上周我们主要对python的基础知识进行了学习,从完全不懂到写出第一段代码,从畏惧发怵到解决第一个代码问题,大家已经从小白迈出了python入门的第一步!你们都是最棒的!那请继续保持着这样的学习动力,趁热打铁,继续我们的课程吧!
本周开始,我们就进入到了项目二(P2)阶段的第二周,需要针对数据分析来学习两个重要的第三方库Numpy和Pandas,它们是python实现科学计算和数据处理的重要库,在以后的数据分析路上会经常用到,所以一定要掌握,并且还要熟练!
| 时间 | 学习重点 | 对应课程 |
|---|---|---|
| 第1周 | Python基础内容 | 数据类型和运算符、控制流、函数、脚本编写 |
| 第2周 | Python数据处理内容 | Numpy & Pandas |
| 第3周 | 完成项目 | 项目:探索美国共享单车数据 |
| 第4周 | 项目修改与通过 | 修改项目、查缺补漏、休息调整 |
对于非小白同学来说,本阶段内容不是很难,希望你们能在三周内完成并通过项目;
对于小白来说,本阶段可能是个挑战,请一定要保持自信,请一定要坚持学习和总结,如果遇到任何课程问题请参照如下顺序进行解决:
- 先自行查找问题答案(注意提取关键词),参考:谷歌/百度搜索、菜鸟教程、CSDN、stackoverflow、Python for Data Analysis, 2nd Edition 、Python Cookbook
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
饭要一口一口吃,路要一步一步走,大家不要被任务吓到,跟着导学一步一步来,肯定没问题哒!那我们开始吧!
注:本着按需知情原则,所涉及的知识点都是在数据分析过程中必须的、常用的,而不是最全面的,想要更丰富,那就需要你们课下再进一步的学习和探索!
本周目标
- 学完课程Numpy&Pandas。
- (可选)项目环境准备。
知识清单
Numpy
NumPy 简介
NumPy 是 Numerical Python 的简称,它是 Python 中的科学计算基本软件包。NumPy 为 Python 提供了大量数学库,使我们能够高效地进行数字计算。更多可点击Numpy官网查看。
关于Numpy需要知道的几点:
- NumPy 数组在创建时有固定的大小,不同于Python列表(可以动态增长)。更改ndarray的大小将创建一个新的数组并删除原始数据。
- NumPy 数组中的元素都需要具有相同的数据类型,因此在存储器中将具有相同的大小。数组的元素如果也是数组(可以是 Python 的原生 array,也可以是 ndarray)的情况下,则构成了多维数组。
- NumPy 数组便于对大量数据进行高级数学和其他类型的操作。通常,这样的操作比使用Python的内置序列可能更有效和更少的代码执行。
所以,Numpy 的核心是ndarray对象,这个对象封装了同质数据类型的n维数组。起名 ndarray 的原因就是因为是 n-dimension-array 的简写。接下来本节所有的课程都是围绕着ndarray来讲的,理论知识较少,代码量较多,所以大家在学习的时候,多自己动动手,尝试自己去运行一下代码。
创建ndarray
课程中所说的,创建一个秩为2的ndarray,实际上指的是创建一个2维的ndarray,并不是矩阵的秩。
- 由python list创建
1 | a = np.array([1, 2, 3]) # 1维数组 |
- 由numpy内置函数创建
1 | a = np.zeros((2,2)) # 创建2x2的全0数组 |
访问、删除、增加ndarray中的元素
这里主要是提供了一些访问、更改或增加ndarray中某一元素的基础方法。
- 访问&更改
类似于访问python list中元素的方式,按照元素的index进行访问或更改。
1 | #访问某一元素,这里可以自己多尝试,摸索 |
- 删除
可使用np.delete(ndarray, elements, axis)函数进行删除操作。
这里需要注意的是axis这个参数,课程中只讲到了2维数据中,axis = 0表示选择行,axis = 1表示选择列,但不能机械的认为0就表示行,1就表示列,注意前提2维数据中。
在三维数据中,axis = 0表示组,1表示行,2表示列。这是为什么呢?提示一下,三位数组的shape中组、行和列是怎样排序的?
所以,axis的赋值一定要考虑数组的shape。
1 | a = np.arange(12).reshape(2,2,3) |
再有一点需要注意的是,如果你想让原数据保留删除后的结果,需要重新替换一下才可以。
1 | a = np.arange(6).reshape(2,3) |
- 增加
往ndarray中增加元素的办法跟python list也很类似,常用的有两种:
一种是添加(append),就是将新增的元素添加到ndarray的尾部
- 语法为:
np.append(ndarray, elements, axis) - 参数和delete函数一致,用法也一致,这里不再赘述
- 语法为:
一种是插入(insert),可以让新增元素插入到指定位置
- 语法为:
np.insert(ndarray, index, elements, axis) - 参数中就多了一个
index,指示的是插入新元素的位置。
- 语法为:
这里值得注意的是,不论是append还是insert,在往多维数组中插入元素时,一定要注意对应axis上的shape要一致。再一个就是,和delete一样,如果你想要更改原数据,需要用a = np.append(a,elements,axis)。
ndarray切片
前面学了选择ndarray中的某个元素的方法,这里我们学习选择ndarray子集的方法——切片。
对于切片大家并不陌生,在list里面我们也接触过切片,一维的ndarray切片与list无异。需要注意的是,就是理解2维及多维ndarray切片。
- 2维矩阵切片
1 | a = np.arange(4*4).reshape(4,4) |
这里可以看出,我们筛选了a矩阵中前三列的所有行,这是如何实现的呢?
切片的第一个元素:表示的是选择所有行,第二个元素:-1表示的是从第0列至最后一列(不包含),所以结果如上所示。
再看一个例子:
1 | a[1:3,:] |
筛选的是第2-3行的所有列。
- 一个常用的切片
以列的形式获取最后一列数据:
1 | a[:,3:] |
以一维数组的形式获取最后一列数据:
1 | a[:,-1] |
上面两种方法经常会用到,前者的shape为(4,1),后者为(4,)。
ndarray筛选
- 选择ndarray的对角线
所用函数为np.diag(ndarray, k=N),其中参数k的取值决定了按照哪一条对角线选择数据。
默认k = 0,取主对角线;
k = 1时,取主对角线上面1行的元素;
k = -1时,取主对角线下面1行的元素。
思考:这个函数只能选择主对角线上的元素,那如果想要获取副对角线上的元素呢?
尝试自己搜索一下关键词numpy opposite diagonal寻找答案。
不建议你直接点getting the opposite diagonal of a numpy array。
- 提取ndarray中的唯一值
所用函数为np.unique(ndarray),注意unique也可以添加参数axis来控制评判唯一值的轴方向,不好理解可以看示例:
1 | a = [[0,1,2], |
- 通过布尔运算筛选
这里在中括号中添加筛选条件,当该条件的结果为True时(即满足条件时),返回该值。
1 | X[X > 10] #筛选数组X中大于10的数据 |
这里需要注意的是,当输入多个筛选条件时,&表示与,|表示或,~表示非。
ndarray运算
- 集合运算
1 | np.intersect1d(x,y) #取x与y的交集 |
- 算术运算
我们可以通过+、-、*、/或np.add、np.substract、 np.multiply 、np.divide来对两个矩阵进行元素级的加减乘除运算,因为是元素级的运算,所以两个矩阵的shape必须要严格一致。
上面涉及到的乘法是元素对应相乘,也就是点乘,那矩阵的叉乘呢?可以了解下numpy.matmul函数。
这里需要注意的是,课程中讲的“可广播”,其实指的就是A和B两个矩阵shape可能不一致,但是A可以拆分为整数个与B具有相同shape的矩阵,这样在进行元素级别的运算时,就会先将A进行拆分,然后与B进行运算,结果再组合一起就可以。这里的A就是“可广播”矩阵。
ndarray排序
我们使用np.sort()和ndarray.sort()来对ndarray进行排序。
相同的是:
二者都可以使用参数axis来决定依照哪个轴进行排序,axis = 0时按照列排序,axis = 1时按照行排序;
不同的是:
np.sort()不会更改原数组;ndarray.sort()会更改原数组。
numpy迷你项目
这里涉及到一个概念,叫做数据标准化。
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
有很多种对数据进行标准化处理的方法,我们课程中选择的是利用数据均值和标准差进行标准化:
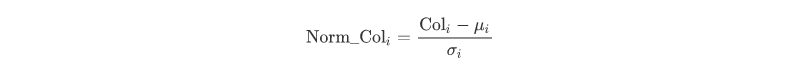
对某一列中某一值进行标准化就是将该值减去该列的平均值,然后除以该列的标准差。标准化后的序列,均值为0,标准差为1,且无量纲。
标准化后的数据,没有量纲,方便计算和比较,在机器学习中的很多算法都需要将数据进行标准化。
但是基于本章的要求,我们主要是学习numpy的基本操作即可,具体的数据标准化还有算法可以之后在机器学习课程中学习。
这里需要注意的是:
np.random.permutation()
np.random.permutation(N) 函数会创建一个从 0 到 N - 1的随机排列的整数集。这个整数集也是ndarray类型。
1 | np.random.permutation(5) |
- 将数据集切分为训练集、测试集和交叉集。
这里的切分有两点隐形要求:
1.随机性,三个数据集中的数据必须是随机分配的;
2.三个数据集的合集必须为数据集。
考虑到上面学到的`np.random.permutation()` 函数,所以我们的思路可以是这样的:
1. 使用`permutation()`函数,将数据集的行数当作N,这样就可以得到一个随机排列的行索引序列;
2. 使用切片,将刚才的随机行索引序列,按照训练集、测试集和交叉集的比例`6:2:2`进行切分;
3. 使用索引访问,获取切分后的数据,即`ndarray[index]`的方式。Pandas
Pandas简介
Pandas 是 Python 中的数据操纵和分析软件包,它是基于Numpy去开发的,所以Pandas的数据处理速度也很快,而且Numpy中的有些函数在Pandas中也能使用,方法也类似。
Pandas 为 Python 带来了两个新的数据结构,即 Pandas Series(可类比于表格中的某一列)和 Pandas DataFrame(可类比于表格)。借助这两个数据结构,我们能够轻松直观地处理带标签数据和关系数据。
Series中各个元素的数据类型可以不一致,DataFrame也是如此,这与numpy的ndarray不同。
创建Pandas Series
可以使用 pd.Series(data, index) 命令创建 Pandas Series,其中data表示输入数据, index 为对应数据的索引,除此之外,我们还可以添加参数dtype来设置该列的数据类型。
示例:
1 | import pandas as pd |
data除了可以输入列表之外,还可以输入字典,或者是直接一个标量。
1 | #data输入字典 |
访问和删除Series中的元素
- 访问
访问Series中的元素有两种方法:
一种类似于从列表中按照索引访问数据,一种类似于从字典中按照key来访问value。
下面看示例:
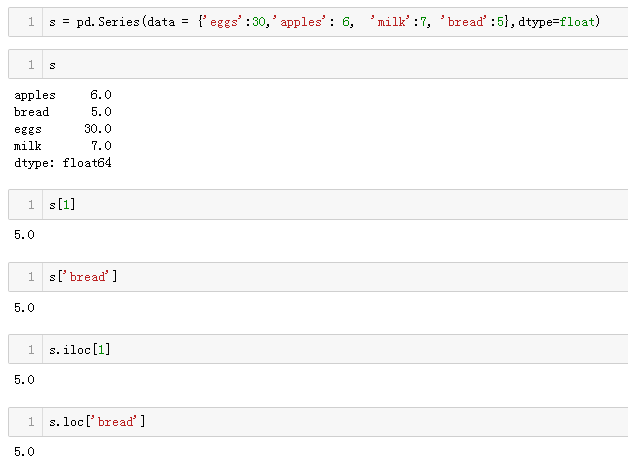
从上面代码里也能发现,Pandas提供的iloc与loc分别对应着按索引访问和按key访问。
- 修改
因为Series是可更改类型,若想更改其中某一项,只需访问它然后重新赋值即可。
- 删除
可以使用 .drop() 方法删除 Pandas Series 中的条目。Series.drop(label) 方法会从给定 Series 中删除给定的 label。这个label可以是单个label或这是label组成的list。
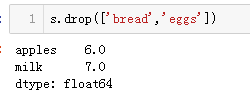
但需要注意的是,.drop()函数并不会修改原来的数据,如果你想要修改原数据的话,可以选择添加参数inplace = True或者是用原数据替换s = s.drop(label)
Series运算
和ndarray一样,Series也可以进行元素级的算术运算,也可以使用np中提供的各种运算函数,如sqrt()等等。
这里可以想一下,如果Series中包含字符串,然后再进行乘法会是什么结果?
可以回想下字符串的知识'*'*10的结果是什么?
创建DataFrame
我们使用pd.DataFrame(data, index, columns)来创建一个DataFrame。
其中:
data是数据,可以输入ndarray,或者是字典(字典中可以包含Series或arrays或),或者是DataFrame;
index是索引,输入列表,如果没有设置该参数,会默认以0开始往下计数;
columns是列名,输入列表,如果没有设置该参数,会默认以0开始往右计数;
示例:
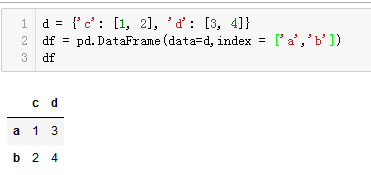
从上述代码中可以看出,字典d中的key被当作列名,value被当作dataframe中的数据。
思考:如果在上述代码中添加一个columns列,如df = pd.DataFrame(data=d,index = ['a','b'],columns = ['col_1','col_2']),会返回什么结果呢?
访问DataFrame中的元素
与访问Series中的元素类似,我们可以通过列表式索引访问,也可以通过字典式Key值访问。
- 创建一个DataFrame
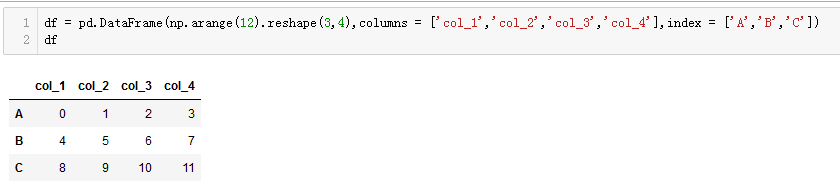
- 访问某一行
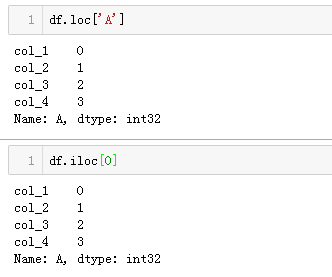
- 访问多行

- 访问某一列

- 访问多列
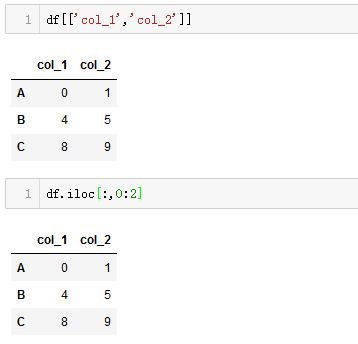
使用df.iloc[:,0:2]这种方法只能筛选出连续的列,那如果想要筛选的列分别在1,3,5,10:17怎么办呢?可以搜一下
np.r_的用法。
- 访问某一行列的元素

删除、增加元素
- 删除元素
我们使用.drop函数删除元素,默认为删除行,添加参数axis = 1来删除列。
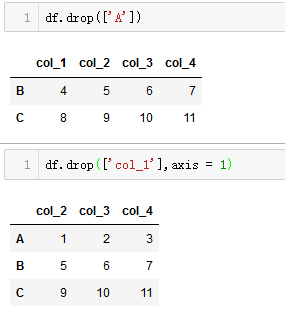
值得注意的是,drop函数不会修改原数据,如果想直接对原数据进行修改的话,可以选择添加参数inplace = True或用原变量名重新赋值替换。
- 增加元素
这里介绍了两种方法,一种是append(),另外一种是insert(),这两种方法都比较简单,可类比于python list中的两种方法进行学习。
此外,Pandas还提供了其他更为复杂的做DataFrame融合的函数,比如说concat()、merge()、join()等等,相对难理解一些,我会单独出一份导学详细介绍这几个数据融合函数。
更改行列标签
使用函数rename()即可。具体用法如下:

除此之外,还可以使用隐匿函数lambda来对行列标签进行统一处理,比如:

需要注意的是,rename()函数同样不会更改原数据,如果想直接对原数据进行修改的话,可以选择添加参数inplace = True或用原变量名重新赋值替换。
更改索引
可以使用函数set_index(index_label),将数据集的index设置为index_label。
除此之外,还可以使用函数reset_index()重置数据集的index为0开始计数的数列。
缺失值(NaN)处理
NaN就是Not a Number的缩写,表示这里有数据缺失。
- 查找NaN
我们可以使用isnull()和notnull()函数来查看数据集中是否存在缺失数据,在该函数后面添加sum()函数来对缺失数量进行统计。除此之外,还可以使用count()函数对非NaN数据进行统计计数。
- 删除NaN
使用dropna(axis)函数可以删除包含NaN的行或列。
dropna()函数还有一个参数是how,当how = all时,只会删除全部数据都为NaN的列或行。
同样,该函数也不会修改原数据集。
- 替换NaN
使用fillna()函数可以替换NaN为某一值。其参数如下:
- value:用来替换NaN的值
- method:常用有两种,一种是
ffill前向填充,一种是backfill后向填充 - axis:0为行,1为列
- inplace:是否替换原数据,默认为False
- limit:接受int类型的输入,可以限定替换前多少个NaN
一般来说,我们常用均值去替换NaN。
还可以使用interpolate()函数按照某一方法来替换NaN,课程中介绍了method为linear时的用法,即忽略索引并将值视为相等间距,这是该函数的默认方法。更多method及解读请戳pandas.DataFrame.interpolate
在Pandas中处理数据
1 | df = pd.read_csv(filename) #读取csv文件 |
项目内容
本首是Python项目的第2周,主要还是理解项目和准备项目文件,请大家做到以下几点:
Project2/week1的项目要求:(应该已经做完)
- 完成/项目:探索美国共享单车数据/的1-3节内容
- 搭建本地anaconda环境(Python3版本)确保Spyder可以使用
- 下载bikeshare-new-2.zip项目文件。如果教室里面不能下载,请尝试下载下面的链接:https://github.com/mengfanchun2017/DAND-Basic/blob/master/Project1/Project1Files/bikeshare-new-2.zip
Project2/week2的项目要求 (本周要求和,做完了画第二个勾勾)
- 用spyder打开项目文件浏览
- 了解项目文件中有几个函数,函数名和输入是什么(不用看明白和尝试做)