It’s not about where your starting point is, but your end goal and the journey that will get you there.
在P2阶段的末尾,课程中涉及到了一个新的pandas函数——merge,有些同学对merge的用法存在疑惑,尤其是查了一下Pandas如何做数据合并之后,发现除了merge之外,还有concat、还有join,还有append,更是一脸懵了,那这期导学呢,我们就来一起梳理一下pandas数据合并的知识点,同学们不要慌,除了代码之外,还嵌入了DataFrame的图片方便大家理解。当然,看完之后还是要自己多练习才行!加油!
merge
官方文档
文档链接
常用参数解读
right:合并的另一个DataFrame
how:数据融合的方式,包括:left、right、outer和inner,默认是inner
merge的连接方式与SQL对比
合并方式 SQL JOIN 描述 leftLEFT OUTER JOIN只用左表的key去匹配链接 rightRIGHT OUTER JOIN只用右表的key去匹配链接 outerFULL OUTER JOIN两表中key的并集 innerINNER JOIN两表中key的交集 on:进行合并的共有列的名字,用到这个参数的时候一定要保证左表和右表的共有列都有相同的列名
left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
left_index/ right_index: 布尔值,如果是True的话,以index作为key
sort:布尔值,会根据dataframe合并的keys按字典顺序(abcd…这种)排序,默认为True,设置为False可以提高运算速率。
合并方法
一对一 : 联接两个 DataFrame 的key唯一
多对一 : 将一个DataFrame的唯一key连接到另一个 DataFrame 中的一个或多个key
- 多对多 : keys 对 keys
实例
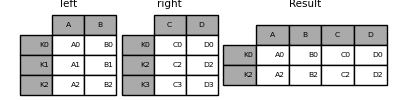
一对一
默认连接方式为inner,即取交集
1 | In [1]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], |
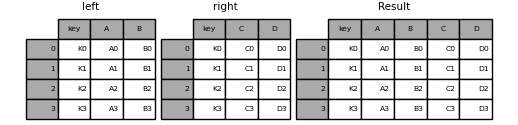
- 多对多(默认内链接)
1 | In [4]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], |

- 左链接
1 | In [7]: result = pd.merge(left, right, how='left', on=['key1', 'key2']) |
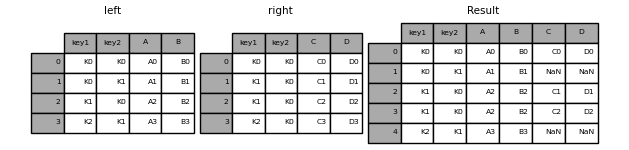
- 右链接
1 | In [8]: result = pd.merge(left, right, how='right', on=['key1', 'key2']) |

- 外链接
1 | In [9]: result = pd.merge(left, right, how='outer', on=['key1', 'key2']) |
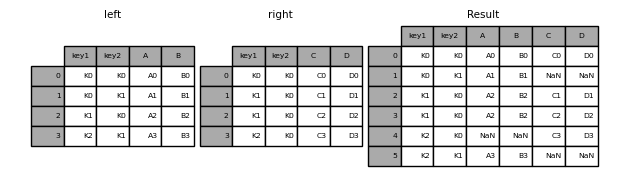
利用index链接
这里就要用到
left_index和right_index参数了,实例如下:1
In [10]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')

重复列的处理
当你进行合并时,key有重复的话,会额外输出行数X重名列数的数据,不仅结果错误,还会导致电脑运行速度巨慢,所以,合并前一定要检查是否有重复列名,当然你可以直接比对两表的列名,或者选择如下方法:
1 | In [10]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]}) |
当有重名列的时候,就会报错,那么如果想继续合并的话,只需把validate参数改为"one_to_many"。
1 | In [13]: pd.merge(left, right, on='B', how='outer', validate="one_to_many") |
如果你想在合并后,把两表中重名的列加上后缀的话,可以使用suffixes参数
1 | In [27]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]}) |
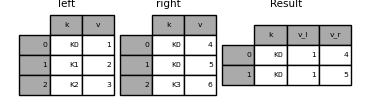
indicator参数
在merge里,还有一个有意思的参数叫indicator,可以输入布尔值(默认为False),当你设置为True的时候,会在你合并的表中,增加一列_merge,元素则表示了合并后的数据来自左表还是右表或者二者皆有。
看示例:
1 | In [14]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']}) |
或者也可以输入一个字符串作为列名:
1 | In [17]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column') |
join
官方文档
文档链接
常用参数解读
- other : DataFrame , 或者是有列名的Series
- on : 也就是merge的key,可以输入key或者keys,默认为index
- how : left、right、outer、inner,默认为left
合并方法
join是一种快速合并方法,所需参数较少,默认以index作为链接键。
实例
- 最常用
1 | In [18]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'], |
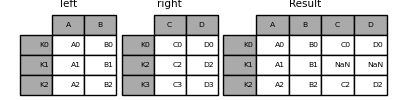
- 外连接
1 | In [21]: result = left.join(right, how='outer') |
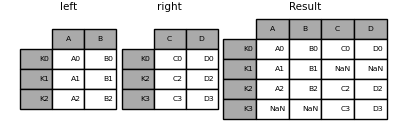
- 内连接
1 | In [22]: result = left.join(right, how='inner') |
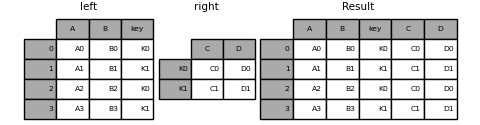
- 键为列与index
1 | In [23]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], |
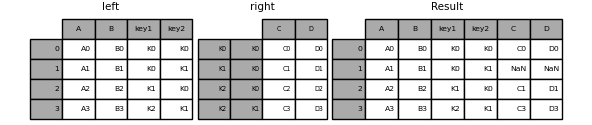
- 键为多列与多index
1 | In [26]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], |
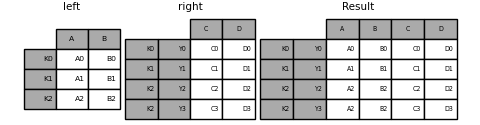
- 键为单index与多重index
1 | In [30]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'], |
你也可以用merge来实现:
2
3
....: on=['key'], how='inner').set_index(['key','Y'])
....:
- 键为两个多重index
这里用join就不能实现了,但是你可以用merge,方法跟上面merge的用法类似
2
3
4
5
6
7
8
9
10
11
12
13
....: ('K1', 'X2')],
....: names=['key', 'X'])
....:
In [36]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=index)
.....:
In [37]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key','X','Y'])
.....:
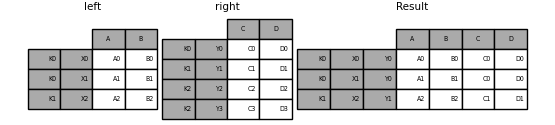
重复列的处理
1 | In [38]: left = pd.DataFrame({ 'v': [1, 2, 3]},index = ['K0', 'K1', 'K2']) |

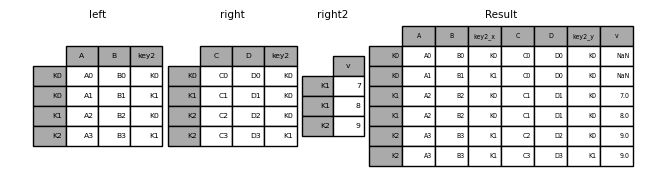
多表的连接
1 | In [41]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2']) |
concat
官方文档
文档链接
常用参数解读
- objs::series或者dataframe
- axis: 需要合并连接的轴,0表示行,1表示列
- join:inner或者outer,默认为outer
合并方法
实例
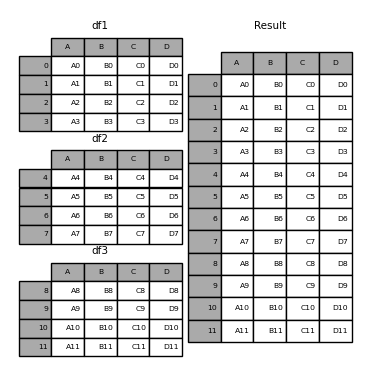
- 纵向连接相同列名的表
1 | In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], |
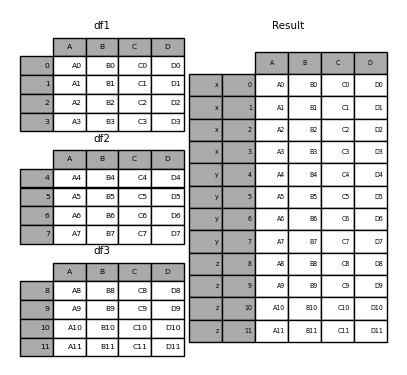
你也可以设置key参数,来区分数据来自哪张表
1 | In [6]: result = pd.concat(frames, keys=['x', 'y', 'z']) |
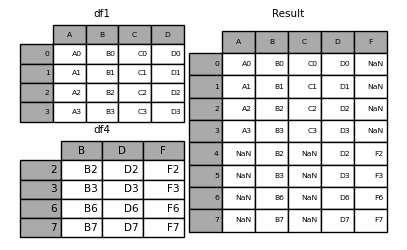
- 行拼接(默认外连接)
1 | In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], |
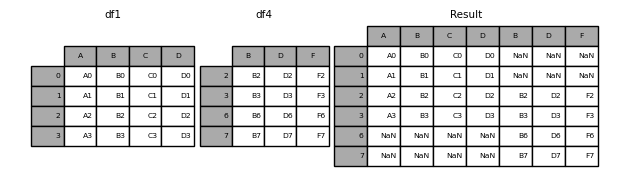
- 行拼接(设置内连接)
1 | In [10]: result = pd.concat([df1, df4], axis=1, join='inner') |

- 行拼接(只筛选出某一表的index)
1 | In [11]: result = pd.concat([df1, df4], axis=1, join_axes=[df1.index]) |

无视index的合并
当数据表的index没有实际意义时,可以使用
ignore_index参数,来重置合并后的数据集index
1 | In [15]: result = pd.concat([df1, df4], ignore_index=True) |
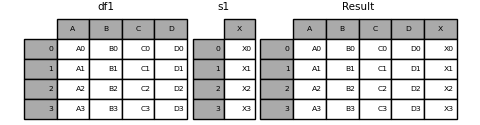
- 合并DataFrame与Series
1 | In [17]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X') |
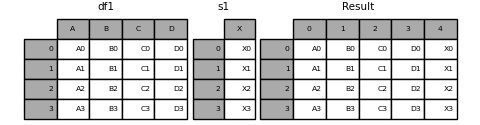
当然你也可以使用ignore_index参数,将列名重置
1 | In [21]: result = pd.concat([df1, s1], axis=1, ignore_index=True) |
- 合并若干Series
1 | In [22]: s3 = pd.Series([0, 1, 2, 3], name='foo') |
你可以添加keys参数,来给合并后的数据集添加列名
1 | In [26]: pd.concat([s3, s4, s5], axis=1, keys=['red','blue','yellow']) |
append
append其实就是concat的一个便捷函数,实现列的拼接
1 | In [12]: result = df1.append(df2) |

- 当两表列名不一致时
1 | In [13]: result = df1.append(df4) |

你可以添加参数
ignore_index = True,来重置合并数据集的index

- 合并多个表
1 | In [14]: result = df1.append([df2, df3]) |

- DataFrame添加Series
1 | In [34]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D']) |
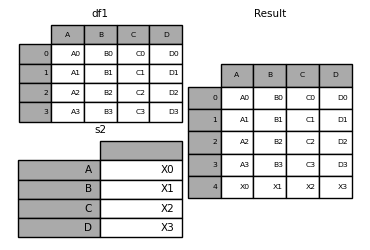
其他
合并两表中的值
你以后也许会在工作中遇到这种情况,你的团队中针对同一情况统计了两份数据,但是这两份数据都有一些缺失值,那么如何让他们相互“弥补”这些缺失值呢?
试试pandas.DataFrame.combine_first
1 | In [43]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan], |
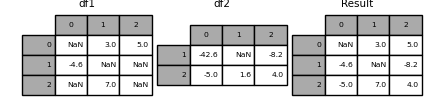
但是,此方法只是利用右表中的值替换了左表中的NaN。
另外,你还可以试试pandas.DataFrame.update,这次替换的不仅仅是NaN值,还有其他所有能在右表中找到的相同位置的值。
1 | In [46]: df1.update(df2) |

总结
- merge主要用来根据key对数据集进行合并;
- join相当于简化版的merge,key默认为index,所以你如果想按照index对数据集合并时,join就是你的首选;
- concat其实是concatenate的简称,翻译过来是“连接”,所以,如果你想对数据集进行横向连接(axis = 1)或者纵向链接时,记得想起来用concat;
- append相当于是简化版的concat,用得频次比concat要多得多。
希望能通过这篇导学,给大家扫除Pandas数据融合的疑惑,当然还是那句话,Learning by doing,光看不练可不行哦,打开你的Jupyter Notebook,试试看!
 、
、