概述
最近在处理自主招生的数据,对于某一个确定的高校来说,录取的人数远远小于未录取的人数,换言之,就是录取类的数据量远小于未录取类的数据量,这就是不平衡数据,虽然在机器学习中不平衡数据的处理不是难点,但这也是我们不得不去考虑的问题,那在本篇文章中,我们便来一起探讨下有哪些处理不平衡数据的技巧。
什么是不平衡数据
不平衡数据,顾名思义,就是指在收集到的数据中各个分类之比并非为1:1,在对不平衡数据的研究中,普遍认为不平衡意味着少数类所占比例在10%到20%之间,但实际上,这种现象可能会更严重,比如说:
- 每年有大约2%的信用卡用户存在欺诈;
- 某种情况的医学筛查,比如说美国的艾滋病得病率约为0.4%;
- 磁盘驱动器的故障率每年约1%;
- 在线广告的转化率约在10-3至10-6之间;
- 文章开头提到的高校录取率,比如某985院校的自主招生审核通过率在0.2%左右。
对于这种不平衡的数据来说,如果不进行数据预处理就应用机器学习算法进行训练,那么得到的模型只需要把所有的结果都预测为多数类那边,就能获得很高的准确率(比如说,对所有的学生都判定为审核未通过,那么准确率会达到1-0.2%=99.8%),但是这其实一点用都没有。
平衡数据大概像是这样:
不平衡数据大概像是这样:
处理不平衡数据
处理不平衡数据的思路比较简单,那就是想办法让数据平衡,我们可以简单得分为以下几类:
- 更改数据集中各分类数据的量,使他们比例匹配——常用方法有采样、数据合成;
- 更改数据集中各分类数据的权重,使他们的量与权重之积匹配——常用方法为加权;
- 不修改数据集,而是在思路上将不平衡数据训练问题转化为一分类问题或者异常检测问题(少数类就像是存在于多数类中的异常值)。
更多更详细研究范畴的分类可以查看这篇论文A Survey of Predictive Modelling under Imbalanced Distributions
那接下来,我们分别看一下各个方法在python中的具体实施。
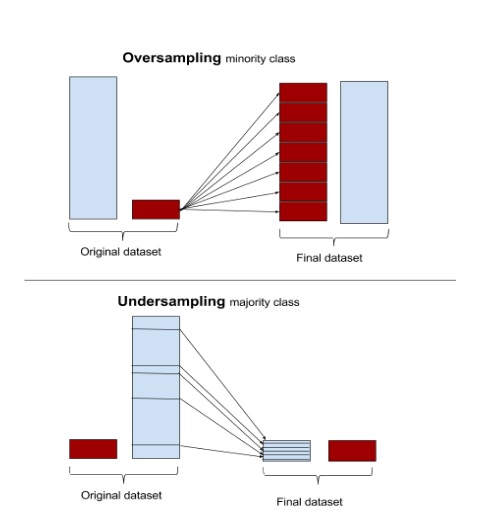
采样
采样就是通过减少多数类数量的下采样(Undersampling)或增加少数类数量的上采样(Oversampling)方式,实现各类别平衡。针对两种采样方式,依赖不同的方法,比如说 随机、模型融合等,就会生成很多解决方案,可以看这篇综述Learning from Imbalanced Data的总结。
代码实现
有一个叫做imbalanced-learn的库,是专门针对不平衡数据设计的,其中包含很多上采样和下采样的函数,官方文档在这里。
示例:
1 | from collections import Counter |
Original dataset shape Counter({1: 900, 0: 100})
1 | #随机下采样 |
Resampled dataset shape Counter({0: 100, 1: 100})
1 | #随机上采样 |
Resampled dataset shape Counter({0: 900, 1: 900})
数据合成
随机上采样会反复出现一些样本,而导致过拟合;随机下采样则会造成一定程度的特征丢失,虽然这种方式比较简单,但现在计算机的计算能力越来越高,可接受的算法复杂度也越来越高,所以我们应该主要考虑模型训练的效果。
数据合成则是利用已有样本生成更多样本,其中常用的包括:
SMOTE,利用KNN生成新数据;SMOTEC,可以合成分类数据,但数据集中至少要包含一条连续数据;如果数据集中全是分类数据的话,可以增加一列全为1的intercept列作为连续数据,合成数据之后,再将该列删除即可。
BorderlineSMOTE,与SMOTE的区别是,只为那些周围大部分是大众样本的小众样本生成新样本(因为这些样本往往是边界样本);
代码实现
1 | from imblearn.over_sampling import SMOTE |
Resampled dataset shape Counter({0: 900, 1: 900})
更改权重
更改权重就是针对不同类别的数据设置不同的分错代价,即提高少数类分错的代价或降低多数类分错的代价,最终使各类别平衡。
常用的机器学习训练方法中,很多都提供了权重设置参数class_weight,可以手动设置该参数,但一般情况下只需要将其设置为balanced即可,模型会自动按照如下公式更新权重:

代码实现
1 | from sklearn.linear_model import LogisticRegression |
一分类
这种方法比较适合极不平衡数据,或数据量比较小的数据集。
主要方法为OneClassSVM,官方文档在这里
代码实现
1 | from sklearn import svm |
异常检测我没怎么用过,所以就不赘述了,感兴趣可以戳这个链接Novelty and Outlier Detection
总结
我们可以依据数据量的大小和是否平衡将数据集分为四类,即平衡的大数据集,不平衡的大数据集,平衡的小数据集,不平衡的小数据集。最简单的就是平衡的大数据集,能达到非常高的准确率,最难的就是不平衡的小数据集,除了在平衡上下功夫之外,还需要很多诸如收集数据、特征工程之类的工作,但这并不是本篇文章的重点。
下面根据个人经验谈下针对如上几种数据集,如何选择文中涉及的这些方法:
- 数据量较小的情况考虑用数据合成的方法,依据特征的类型(分类&连续数值)选择合适的方法。
- 数据量还可以,但类别之间数量相差悬殊的时候考虑用一分类或者异常检测的方法。
- 数据量还可以,而且类别之间数量相差不是特别悬殊的情况,考虑用采样或者更改权重的方法。
具体数据量的大小可以参考下图:

参考

本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。