If you change nothing, nothing will change.
Hi,各位同学们,大家好,欢迎踏上数据分析的不归路列车~在发车之前,有几点需要给大家强调一下:
课程和项目:
- 课程以项目为导向,学习曲线十分平缓,我也是从一个小白一步步走过来的,所以请大家一定要对自己有信心
- 从Teambition中,大家也能看到,我们把整体的一个大任务(入门毕业)拆分成了四个子任务(项目),在每个子任务中又拆分成了知识学习、项目提交和修改、总结沉淀三个部分,在这三个部分之中,大家还可以自行再进行切分,如此将一个大难题拆分成若干个小问题,逐个击破,十分轻松
- 对于项目,大家一定要重视!切不可抄袭,一定要对自己负责任
如何提问:
在课程学习中难免会遇到问题,请按照以下流程进行问题提问:
课程知识问题:
- 先自行查找问题答案,参考:谷歌/百度搜索、菜鸟教程、CSDN、stackoverflow、SQLCookbook
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
非课程知识问题:
比如账号登录、课程加载等问题,请详细描述问题,反馈给班主任即可
该说的也说了个差不多,那么,请大家系好安全带做好觉悟:
- 工作可能会很忙,但是每天至少要抽出一个小时来坚持学习,否则一日废,日日废
- 准备好一个笔记本或者有道云笔记、EverNote这种电子笔记本,用来记录学习笔记/问题
- 自律,自律,自律!自律才能让你更自由!
准备发车!
本周目标
学习课程SQL初探,并完成(通过)项目一。
学习计划
| 时间 | 学习资源 | 学习内容 |
|---|---|---|
| 周二 | 微信群 - 每周导学 | 预览每周导学 |
| 周三、周四 | Udacity - Classroom | SQL初探、项目一 |
| 周五 | 微信/Classin - 1V1 | 课程难点 |
| 周六 | Classin - 优达日 | 项目串讲 |
| 周日 | 笔记本 | 总结沉淀 |
| 周一 | 自主学习 | 查漏补缺 |
本周知识清单
课程内掌握
SQL - 格式化查询语句
命令需要大写,其他内容如变量等则需要小写
表和变量名中不要出现空格,可使用下划线
_替代查询语句中,使用单一空格隔开命令和变量
为提高代码的可移植性,请在查询语句结尾添加一个分号
;正确示范
1 | SELECT account_id |
SQL - 基础命令及用法参考
| 语句 | 使用方法 | 其他详细信息 |
|---|---|---|
| SELECT | SELECT Col1, Col2, … | 提供你需要的列 |
| FROM | FROM Table | 提供列所在的表格 |
| LIMIT | LIMIT 10 | 限制返回的行数 |
| ORDER BY | ORDER BY Col | 根据列命令表格。与 DESC 一起使用。 |
| WHERE | WHERE Col > 5 | 用于过滤结果的一个条件语句 |
| LIKE | WHERE Col LIKE ‘%me%’ | 仅提取出列文本中具有 ‘me’ 的行 |
| IN | WHERE Col IN (‘Y’, ‘N’) | 仅过滤行对应的列为 ‘Y’ 或 ‘N’ |
| NOT | WHERE Col NOT IN (‘Y’, “N’) | NOT 经常与 LIKE 和 IN 一起使用。 |
| AND | WHERE Col1 > 5 AND Col2 < 3 | 过滤两个或多个条件必须为真的行 |
| OR | WHERE Col1 > 5 OR Col2 < 3 | 过滤一个条件必须为真的行 |
| BETWEEN | WHERE Col BETWEEN 3 AND 5 | 一般情况下,语法比使用 AND 简单一些 |
示例:
1 | SELECT col1, col2 |
SQL - 运算顺序
在 SQL 中使用算术运算符时,采用与数学中相同的运算顺序。
在 SQL中使用逻辑运算符时,要参考如下优先级顺序(操作符优先级由低到高,排列在同一行的操作符具有相同的优先级)
优先级 操作符列表 1 := 2 ||,OR,XOR 3 &&,AND 4 NOT 5 BETWEEN,CASE,WHEN,THEN,ELSE 6 =,<=>,>=,>,<=,<,<>,!=,IS,LIKE,REGEXP,IN 7 | 8 & 9 <<,>> 10 -,+ 11 *,/,DIV,%,MOD 12 ^ 13 - (一元减号),~ (一元比特反转) 14 ! 15 BINARY,COLLATE HINT:看到如上这么复杂难记的优先级表,想必你也会头大,所以,为了避免因优先级导致的逻辑错误,请一定要将逻辑语句加上小括号,这样既清晰又不易出错!
课程外了解
实体关系图(Entity Relationship Diagram,ERD),是一种用于数据库设计的结构图。一幅 ERD 包含不同的符号和连接符,用于显示两个重要的信息: 系统范围内的主要实体,以及这些实体之间的相互关系。
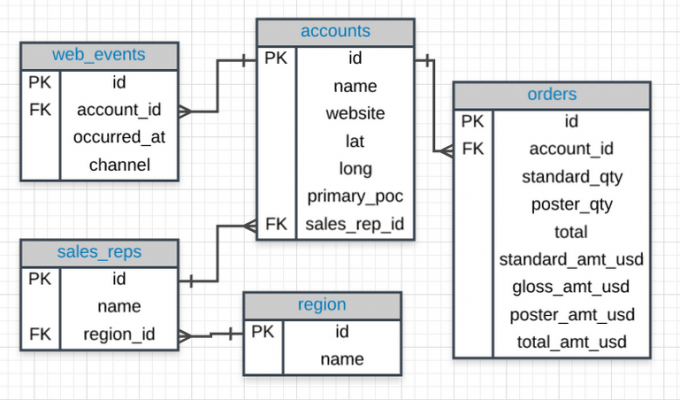
实体:是一个系统内可定义的事物或概念(术语“实体”通常用来代替“表”,但它们是一样的 ),如上图中的
accounts、orders等,即为实体。主键(Primary Key,PK):是一种特殊的实体属性,用于界定数据库表中的记录的独特性。一个表不能有两笔(或更多)拥有相同的主键属性值的记录。在上图中,各个实体内的
id即为PK。外键(Foreign Key,FK):是对主键的引用,用于识别实体之间的关系。请注意,有别于主键,外键不必是唯一的,多个记录可以共享相同的值。 在上图中,
orders表中的account_id即为链接表accounts的外键。基数:基数定义了一个实与另一个实体的关系里面,某方可能出现次数。 三种常见的主要关系是一对一,一对多和多对多。
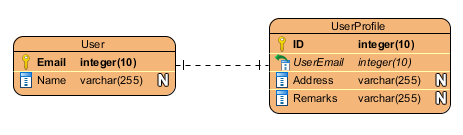
一对一:
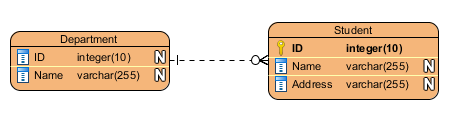
一对多:在课程中的例子即为一对多。
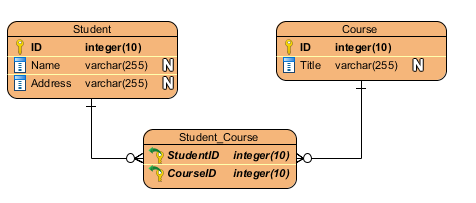
多对多:
项目相关
请先自行尝试完成项目,如果感觉吃力,再参考哈~
项目概览
在这个项目中,我们利用Udacity的数据库,分别提取本地和全球的气温数据,并进行可视化对比分析,观察可视化结果,给出本地及全球平均气温的走势结论。
模块化任务
数据提取
利用SQL,在项目工作区中,提取出全球气温数据和感兴趣城市的数据。
HINT:
在提取感兴趣的城市之前,可以先通过如下代码查看数据库中,是否存在该城市数据
1
2
3SELECT *
FROM city_list
WHERE city = xxx提取出数据之后,可以先在工作区简单预览下,查看有连续记录数据的年份区间,并以这个区间作为筛选条件,重新提取数据并保存
你提取出来的两个数据文件,在时间筛选上应该是一致的
数据整理
利用Excel或Google Sheet对两组数据进行预处理,计算出平均气温的移动平均值
HINT:
- 计算移动平均值采用的函数为
AVERAGE - 两组数据的移动平均值要单独成列,并且有一个不与其他列重复且易于辨认的列名,如
global_temp - 为方便分析,你需要将两列数据合并到同一个文件中,注意在复制粘贴时,选择
粘贴选项->值和数据格式,这样才会粘贴得到公式计算后的数据。
数据可视化及分析
利用Excel或Google Sheet将两组移动平均值进行线条图可视化,并对结果进行描述。
结论
对可视化的分析结果进行总结,并发表结论性看法。
项目提交
提交前,请将 PDF 格式的文档压缩成zip格式的压缩包,文件名不要出现汉字或者空格,示例Allen_project_01.zip
项目提交、收到审阅结果之后请及时告知班主任或助教,让我们一起分享你的喜悦,提前祝项目顺利通过,等你好消息!
参考
提前通关了怎么办?
- 整理学习笔记
- 开始下一阶段的学习:找助教要下一周的导学呀~